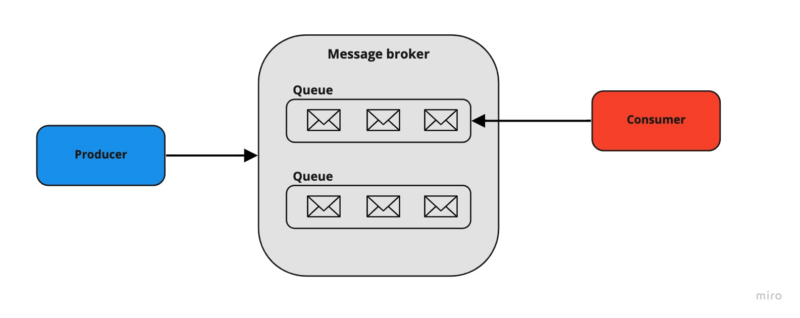
메시지 브로커란?
메시지 브로커는 데이터를 주고받는 시스템 간의 "중간 다리" 역할을 합니다.
- 데이터를 보내는 쪽(프로듀서)과 받는 쪽(컨슈머)을 연결해주는 도구입니다.
- 예를 들어, 주문을 처리하는 시스템과 결제를 처리하는 시스템이 있다면, 메시지 브로커가 두 시스템 사이에서 데이터를 안전하게 전달합니다.

RabbitMQ와 Kafka: 메시지 브로커의 두 강자 비교

RabbitMQ와 Kafka는 서로 다른 방식으로 메시지를 관리하고 전달하는 대표적인 메시지 브로커입니다. 두 시스템은 각각의 강점이 있어, 사용 목적에 따라 적절히 선택할 수 있습니다. 이번 글에서는 RabbitMQ와 Kafka의 차이점과 주요 특징을 쉽게 이해할 수 있도록 설명드리겠습니다.
1. RabbitMQ: 작업 큐와 메시지 라우팅에 강한 메시지 브로커
RabbitMQ는 작업 큐(Work Queue)와 다양한 메시지 라우팅 방식 덕분에 특정 작업 처리를 병렬로 분배하거나, 메시지를 카테고리별로 전달하는 데 매우 유용합니다.
RabbitMQ의 주요 특징
- 작업 큐(Work Queue)
- 메시지를 큐에 저장하고, 여러 작업자(컨슈머)에게 분배하여 병렬 작업을 수행합니다.
- 사용 사례:
- 이미지 처리 시스템: 사용자가 이미지를 업로드하면 큐에 메시지를 저장하고, 여러 컨슈머가 이를 병렬로 처리합니다.
- 알림 서비스: 이메일, SMS, 푸시 알림을 분리하여 각각 처리.
- 메시지 전달 방식이 다양
- 메시지를 라우팅 키(Routing Key), **교환기(Exchange)**를 활용해 다르게 전달할 수 있습니다.
- RabbitMQ의 라우팅 방식:
- Direct Exchange: 특정 키를 가진 메시지만 컨슈머에 전달.
- Fanout Exchange: 메시지를 모든 컨슈머에 전달(브로드캐스트).
- Topic Exchange: 키 패턴(예: *.info)을 기반으로 메시지를 전달.
- 유연성
- RabbitMQ는 Smart Broker로 설계되어, 메시지 전달 로직을 브로커가 관리합니다.
- 다양한 프로토콜(AMQP, MQTT 등)을 지원해 여러 환경에서 쉽게 사용할 수 있습니다.
RabbitMQ의 메시지 처리 방식
- 메시지는 기본적으로 메모리 기반 큐에 저장됩니다.
- 이로 인해 빠른 속도로 메시지를 처리할 수 있지만, 유실 위험이 있습니다.
- Persistent Queue(디스크 저장) 설정을 통해 유실을 방지할 수 있습니다.
2. Kafka: 대용량 데이터를 빠르게 처리하는 로그 중심 브로커
Kafka는 **로그(log)**를 기반으로 메시지를 저장하고 처리하는 데 강점이 있는 브로커입니다. 주로 실시간 스트리밍 데이터 처리나 대규모 시스템의 로그 분석에 사용됩니다.
Kafka의 주요 특징
- 로그 기반 메시지 저장
- Kafka는 메시지를 디스크에 로그처럼 기록합니다.
- 메시지를 소비해도 삭제되지 않으므로, 컨슈머는 필요할 때 다시 데이터를 읽을 수 있습니다.
- 사용 사례:
- 실시간 데이터 스트리밍: 사용자 행동 로그, 애플리케이션 이벤트 수집.
- 데이터 분석: 대규모 데이터를 빠르게 저장하고 처리.
- 고속 처리와 확장성
- Kafka는 Dumb Broker로 설계되어, 브로커가 단순히 메시지를 저장하고 전달하는 역할만 합니다.
- 복잡한 처리는 컨슈머가 담당하며, 이를 통해 초당 수백만 건의 메시지 처리가 가능합니다.
- 컨슈머 그룹
- Kafka는 여러 컨슈머 그룹이 하나의 토픽에서 데이터를 각각 읽을 수 있도록 설계되었습니다.
- 이를 통해 여러 애플리케이션에서 동일한 메시지를 재사용할 수 있습니다.
- 메시지 유실 방지
- 메시지는 디스크에 기록되므로, 브로커가 중단되더라도 데이터가 유실되지 않습니다.
3. RabbitMQ와 Kafka의 주요 차이
특징RabbitMQKafka
| 메시지 저장 방식 | 큐 기반 저장 (기본적으로 메모리, 옵션으로 디스크) | 로그 기반 저장 (디스크에 지속적으로 기록). |
| 브로커 역할 | Smart Broker (라우팅, 메시지 상태 관리 포함). | Dumb Broker (저장과 전달만). |
| 속도 | 메모리 큐일 때 빠르지만, 디스크 큐는 느림. | 초당 수백만 건 처리 가능. |
| 전달 보장 | 브로커가 관리 (ACK 및 Persistent 설정으로 보장). | 컨슈머가 관리 (오프셋 추적). |
| 유실 가능성 | 기본 메모리 큐에서는 유실 가능성 있음. | 디스크 기반이라 유실 가능성 낮음. |
| 메시지 라우팅 | 다양한 라우팅 방식 지원 (Direct, Fanout, Topic). | 토픽 단위로 단순하게 처리. |
| 사용 사례 | 작업 분배, 알림 서비스, 소규모 메시지 처리. | 대규모 로그 저장, 실시간 스트리밍, 데이터 분석. |
4. RabbitMQ vs Kafka: 언제 사용해야 할까?
RabbitMQ를 선택할 때
- 작업 분배가 중요한 경우:
- 작업 큐를 통해 여러 작업자가 병렬로 처리해야 할 때.
- 다양한 메시지 전달 방식이 필요한 경우:
- 메시지를 특정 카테고리, 그룹, 또는 모든 컨슈머에게 다르게 전달해야 할 때.
- 작은 규모의 시스템에서 사용:
- 메시지 트래픽이 크지 않은 환경에서 유연하고 간단한 메시지 처리가 필요할 때.
Kafka를 선택할 때
- 대용량 데이터를 빠르게 처리해야 하는 경우:
- 초당 수백만 건의 데이터를 저장하고 처리해야 할 때.
- 데이터 유지가 중요한 경우:
- 메시지를 로그처럼 기록하여 재처리하거나 분석해야 할 때.
- 실시간 데이터 스트리밍 환경에서 사용:
- IoT 센서 데이터, 사용자 행동 로그 등 실시간 분석이 필요한 경우.
5. 결론
- RabbitMQ는 작업 큐와 다양한 라우팅 방식 덕분에 작업 분배 및 복잡한 메시지 전달이 필요한 시스템에 적합합니다.
- Kafka는 로그 기반 메시지 저장과 고속 처리 덕분에 대규모 데이터 분석과 실시간 스트리밍 환경에서 뛰어난 성능을 발휘합니다.
둘 중 어떤 도구를 선택할지는 프로젝트의 요구사항과 트래픽 규모에 따라 결정됩니다. 필요하면 RabbitMQ와 Kafka를 함께 사용하는 것도 가능하니, 유연하게 설계해보세요! 😊
참고 자료:
https://ademcatamak.medium.com/what-is-message-broker-4f6698c73089
What is Message Broker?
Message broker is a component used for applications to communicate with each other. It provides the exchange of information between…
ademcatamak.medium.com
https://www.openlogic.com/blog/kafka-vs-rabbitmq
Kafka vs. RabbitMQ: Comparing Features and Use Cases | OpenLogic by Perforce
Get an overview of Kafka vs. RabbitMQ, including key features, functionality, and use cases, in this blog.
www.openlogic.com
'IT' 카테고리의 다른 글
| DAO와 Repository: 차이점과 함께 사용하는 이유는 무엇일까요? (0) | 2024.11.24 |
|---|---|
| Spring Boot 프로젝트를 GitHub에 업로드하는 방법 (1) | 2024.11.23 |
| 코틀린이란 무엇인가, 그리고 왜 필요한가? (1) | 2024.11.20 |
| 완벽한 세상을 위한 한걸음 패스키란? (1) | 2024.11.20 |
| 자바에서의 Optional 사용법 및 NullPointerException 방지 (0) | 2024.11.19 |